2-2 데이터 전처리
numpy(넘파이) : 배열 라이브러리
import numpy as np #넘파이 라이브러리 임포트- column_stack() : 전달 받은 리스트를 일렬로 세운 다음 차례대로 나란히 연결 후 tuple(튜플)로 전달

- np.ones() / np.zeros() : 각각 원하는 개수의 1,0을 채운 배열을 만들어줌

-np.concatenate() : 첫 번째 차원을 따라 배열을 연결하는 함수

>> 데이터가 클수록 파이썬 리스트는 비효율적이므로 넘파이 배열을 사용하는 게 좋음
사이킷런 : 머시러닝 모델을 위한 알고리즘뿐만 아니라 다양한 유틸리티 도구 제공
- train_test_split() : 전달되는 리스트나 배열을 비율에 맞게 훈련세트와 테스트 세트로 나눔
from sklearn.model_selection import train_test_split* random_state 변수 : 자체적으로 랜덤시드를 지정할 수 있는 매개변수
사이킷런으로 훈련 세트 / 테스트 세트 나누기
train_input, test_ input, test_target = train_test_split(fish_data, fish_target, random_state = 42)
*shape : 넘파이 배열의 속성으로 입력 데이터의 크기를 출력
print(train_input.shape, test_input.shape)
>> (36,2) (13,2) # 2차원 배열
print(train_target.shape,test_target.shape)
>> (36,) (13,) #1차원 배열print(test_target)
>> [ 1. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1.]13개 테스트 중에 10개가 1(도미), 3개가 0(빙어) --> 비율이 3.3:1 ( 샘플링 편향 )
* stratify 매개변수 : 타깃 데이터를 전달하면 클래스 비율에 맞게 데이터를 나눔
train_input, test_input, train_target, test_target
= train_test_split(fish_data, fish_target, stratify = fish_target, random_state = 42)print(test_target)
>> [0. 0. 1. 0. 1. 0. 1. 1. 1. 1. 1. 1. 1.]13개 테스트 중에 9개가 1(도미), 4개가 0(빙어) --> 비율이 2.25:1 (데이터 준비 완료)
k-최근접 이웃 훈련
k-최근접 이웃은 주변의 샘플 중 다수인 클래스를 예측으로 사용
KNeighborsClassifier 클래스 : 주어진 샘플에서 가장 가까운 이웃을 찾아 주는 kneighbors() 메서드 제공
KNeighborsClassifier 클래스의 n_neighbors의 default값은 5
import matplotlib.pyplot as plt
plt.scatter(train_input[:,0],train_input[:,1]
plt.scatter(25,150,marker ='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
새로운 샘플은 marker = '^' 로 지정하여 삼각형으로 나타냄
이 샘플은 빙어 데이터로 예측함
-> 5개의 이웃으로 판단하기 때문
x축의 범위가 좁고 y축은 범위가넓어서 y축으로 조금만 멀어져도 거리가 매우 큰 값으로 계산됨.
-> x, y 축 범위를 동일하게 바꿔야 함
*xlim() : x축 범위 지정 ylim() : y축 범위 지정
plt.scatter(train_input[:,0],train_input[:,1]
plt.scatter(25,150,marker ='^')
plt,scatter(train_input,0],train_input[indexs,1],marker='D')
plt.xlim((0,1000))
plt.xlabel('length')
plt.ylabel('weight')
plt.show()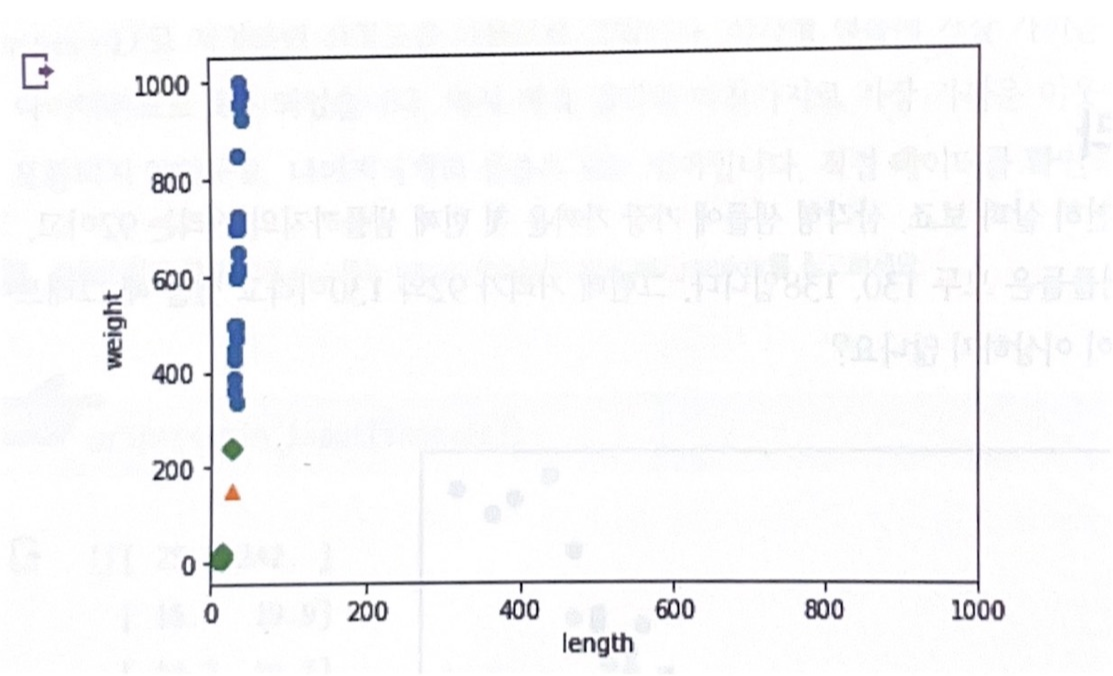
생선의 길이 (x축)은 가장 가까운 이웃을 찾는데 크게 영향 X, 생선의 무게(y축)만 고려 대상
>> 두 특성의 스케일 scale 이 다름<<
데이터 전처리(data preprocessing)
: 알고리즘은 샘플 간의 거리에 영향을 많이 받으므로 특성값을 일정한 기준으로 맞춰 줘야함
표준 점수: 각 특성값이 0에서 표준편차의 몇 배만큼 떨어져 있는지를 나타내는 가장 많이 사용하는 전처리방법
mean = np.mean(train_input, axis=0) # 평균을 계산
std = np.std(train_input,axis=0) # 표준편차를 계산
*axis=0 은 행을 따라 각 열의 통계 값을 계산
*axis=1 은 열을 따라 각 행의 통계 값을 계산new = ([25,150] - mean) / std
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker = '^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
print(kn.predict([new])
>> [1. ]<정리>
대부분의 머신러닝 알고리즘은 특성의 스케일이 다르면 잘 작동하지 않음.
표준점수(전처리 방법) 변환을 통해 문제점 해결
데이터 전처리를 할 때 주의할 점은 훈련세트를 변환한 방식 그래도 테스트 세트를 변환해야함.
'공부 > Deep Learning' 카테고리의 다른 글
| 혼자 공부하는 머신러닝 + 딥러닝 9장 (1) | 2023.11.25 |
|---|---|
| 혼자 공부하는 머신러닝 + 딥러닝 8장 (2) | 2023.11.19 |
| 혼자 공부하는 머신러닝 + 딥러닝 7장 (1) | 2023.11.12 |
| 혼자공부하는 머신러닝 + 딥러닝 5장 (0) | 2023.10.28 |
| 혼자 공부하는 머신러닝+딥러닝 4장 (0) | 2023.10.04 |


