[Paper Review] Noise2Noise: Learning image restoration without clean data
Abstract
- 기존의 신호 재구성 방식과 달리 오직 손상된 예시만을 바라보고 이미지를 복원하는 방법을 학습할 수 있는지에 대한 통계적 추론을 적용
-> 손상된 데이터만을 보고 이미지 복원을 학습할 수 있고 , 깨끗한 데이터를 사용할 때보다 더 나은 성능을 보일 수 있음.
ex) 손상된 사진의 노이즈 제거, 합성 Monte Carlo images의 denoising, 샘플링이 부족한 restruction of undersampled MRI scans
based on noisy data only
1. Introduction
Signal reconstruction from corrupted or incomplete measurements ; 통계적 데이터 분석의 중요한 분야
-> 대규모의 손상된 입력과 깨끗한 대상 쌍을 사용해 회귀모델 (CNN) 훈련을 통해 이루어짐
주어진 손상된 입력에 대해 신경망이 깨끗한 이미지를 예측하도록 훈련하는 과정

** 깨끗한 학습 데이터의 필요성을 없애고, 많은 실제 응용 프로그램에서 학습된 신호 재구성을 용이하게 함 **
이 수식은 주어진 손상된 입력에 대해 신경망이 깨끗한 이미지를 예측하도록 훈련하는 과정을 나타냅니다. 신경망은 손실 함수 의 값을 최소화하는 방향으로 매개변수 를 조정하며 학습합니다. 이 과정을 통해 신경망은 손상된 입력에서 깨끗한 이미지로 매핑하는 방법을 학습
2. Theoretical Background
방의 온도를 측정하는 불확실한 측정치 (y21,y2,y3, ... ) 의 집합을 가지고 있을 때 실제온도를 측정 하는 예시
estimating the true unknown temperature's strategy
-> 손실함수 L에 따른 측정치로부터의 평균 편차가 가장 작은 숫자 z를 찾는 과정

L1 loss : L(z,y) = | z- y | 의 경우 median 값을 추정함
L2 loss : L(z,y) = (z - y)^2 의 경우 mean 값을 추정함.
신경망은 입력 데이터의 의존성을 제거하고 각 입력 샘플에 대해 이 포인트 추정 문제를 별도로 해결함으로 손실 최소화
이 수식은 loss (즉, 평균 제곱 오차)를 최소화하는 추정치 가 관측값 의 기대값(산술 평균)에서 발견될 수 있다는 것을 나타냅니다.
간단히 말해서, 관측치의 평균이 가장 적은 편차를 보이는 추정치
image Denoising 을 할 때 생각하면, input 과 target 간의 1:1 mapping이 아니고 다중 값 mapping 이 이뤄짐.
여기에 L2 loss 를 적용한다면 네트워크는 모든 가능한 target의 경우를 평균낸 결과를 학습하고 결과에 blurriness 효과가 있을 수 밖에 없음 (perceptual loss 를 쓰는 이유)

논문에서는 L2 loss 가 모든 가능한 target의 경우를 평균내는 점을 이용함.
모든 가능한 경우를 평균낸 최적의 output z (denoised image) 를 식으로 나타낸 것임
y가 항상 clean image일 필요는 없음. 각 L2 loss 에서 각 y가 random numbers여도 expectation만 target과 일치하면 같은 방법을 최적의 z를 찾을 수 있음.
이로써 신경망을 통해 손상된 목표를 사용해 학습할 수 있음.

여기서 입력과 목표 모두 손상된 분포에서 가져옴. 이론적으로는 깨끗한 목표 데이터를 사용할 때와 동일한 학습 결과를 얻을 수 있음.
** 이 접근법은 손상 가능성 모델이나 깨끗한 이미지의 밀도 모델없이도, 학습 데이터로부터 이러한 모델을 간접적으로 학습할 수 있음.

왼쪽이 원래 기존에 많이 하는 방법, 오른쪽이 논문에서 제안한 방법
Averge gradient를 통해 주위의 noisy target으로 부터 clean target을 얻게 되는 것을 보여줌.
3. Practical Experiments
3.1. Additive Gaussian Noise
synthetic additive Gaussian Noise 를 사용하여 손상된 대상(target) 의 효과를 연구
noise가 평균이 0이므로 평균을 복구하기 위해 L2 loss를 훈련에 사용
"RED30" 사용 ; gaussian noise 를 포함한 다양한 이미지 복원작업에서 매우 효과적인 30layer hierachical residual network
IMAGENET 검증세트에서 256x256 픽셀 크기의 이미지를 무작위로 선택하고, 각 훈련 예제에 대해 노이즈의 표준편차를 [0,50] 범위에서 무작위로 조정. 네트워크는 노이즈를 제거하는 동시에 그 크기를 추정해야함 -> " blind noising "
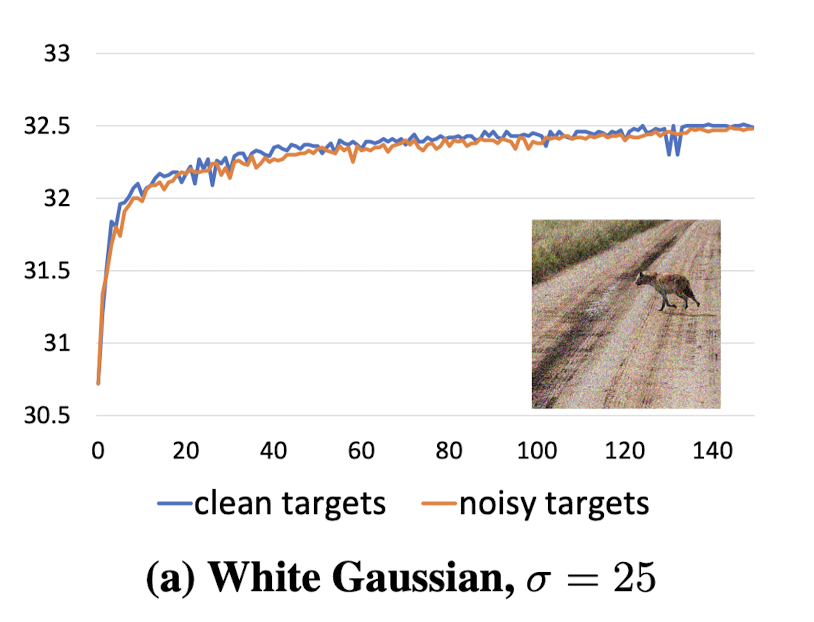

noise target를 사용해 훈련을 수정했을 때, denoising 성능은 좋게 유지
훈련이 clean target을 사용할 때만큼 빠르게 수렴
깨끗한 타겟을 사용하여 훈련할 때 RED30은 σ = 25에서 31.63 ± 0.02 dB를 달성합니다. 비교 대상인 BM3D(Dabov et al., 2007)는 약 0.7 dB 낮은 결과를 보입니다.
-> "이 RED30 에서 clean target이 필요하지 않다" 는 결론.
Convergence speed (수렴속도)
더 크고 노이즈가 많은 gradient 가 수렴 속도에 영향을 주지 않는 이유는?
activation gradient 는 noise가 많지만, weight gradient 는 상대적으로 clean 함
-> Gaussian noise is independent & identically distributed (i.i.d) ,
weight gradient 는 fully convolutional network 에서 2^16에 걸쳐 평균화 되기 때문
Brown Gaussian noise ; noise에 픽셀간 상관관계를 도입.
- spatial Gaussian filter를 사용해 White Gaussian noise를 blurring 하고 다른 bandwidth를 사용한 후 σ = 25를 유지하기 위해 스케일링하여 얻어짐.

상관관계가 증가함에 따라 weight gradient 의 효과적인 평균화는 감소하고, weight update 는 더 noiser
-> convergence slower, but extreme blur, 최종 quality는 비슷
Finite data and capture budget ( 유한 데이터와 캡처 예산)
이전의 연구는 깨끗한 이미지에 synthetic noise 를 clean images 를 추가해 무한히 많은 noise가 있는 예제의 사용 가능성에 의존함
이제는 실제적인 finite data 와 capture budget 상황에서 손상된 훈련데이터와 깨끗한 훈련데이터를 비교함
setting
- 하나의 ImageNet 이미지가 gaussian noise와 함께 "Capture Unit(CU)" 에 해당한다고 가정
- σ = 25 에서 하나의 노이즈가 있는 relization 과 clean version (19개의 noisy realization의 평균) 이 20 CU 를 소비한다고 가정
- 2000CUs 의 총 capture budget을 고정함 ( 깨끗한 latents 이미지 (N)와 각 latent 이미지당 noise relization (M) 사이에서 할당할 수 있음. N * M = 2000

Case 1 ) traditional senario : 100개의 훈련쌍 ( N =100, M = 20)
깨끗한 이미지와 대응하는 하나의 노이즈가 있는 realization (19개의 노이즈가 있는 이미지의 평균)
이 경우는 전통적인 캡처 방식을 나타냅니다. 즉, 깨끗한 이미지와 노이즈가 있는 이미지의 한 쌍만을 사용하여 훈련합니다. 이 방식은 상대적으로 낮은 PSNR을 보여주고 있으며, 이는 적은 수의 높은 품질 데이터보다는 다양한 노이즈 실현을 통한 훈련이 더 효과적임을 암시합니다.
Case2) (N = 100 ,M = 20, average of 19 noisy images)
각 레이턴트 이미지에 대해 가능한 모든 19 * 20 noise/clean 쌍을 형성하여 손상된 타겟을 가진 38,000개의 훈련 쌍으로 사용하는 것이 전통적인 고정된noise+clean 쌍보다 눈에 띄게 더 나은 결과(몇 .1s dB)를 얻는다는 것을 우리는 먼저 관찰함
이 경우는 깨끗한 이미지 대신 노이즈가 있는 이미지를 다양하게 사용하여 훈련하는 방식입니다. 즉, 각 깨끗한 이미지에 대해 가능한 모든 노이즈 실현을 포함시켜 훈련 세트를 확장함. Case1보다 높은 PSNR 달성
Case 3 (N2N, Noise2Noise): 이 경우는 '노이즈에서 노이즈로' 학습을 의미하며, 노이즈가 있는 여러 실현을 사용하여 훈련합니다. 특히, 깨끗한 이미지를 전혀 사용하지 않고 노이즈가 있는 이미지만을 사용하여 네트워크를 훈련합니다. 이 접근법은 Case 2와 유사하거나 약간 더 높은 PSNR을 달성하며, 이는 많은 수의 손상된 데이터를 사용하는 것이 디노이징 성능에 긍정적인 영향을 미침..
"We conclude that for additive Gaussian noise, corrupted targets offer benefits over clean targets on two level.
1) 동일한 latent 깨끗한 이미지에 대한 손상의 더 많은 realization 봄
2) 적은 수의 손상된 realization이라도, 더 많은 latent clean 이미지를 보는 것이 유익함
3.2 Other Synthetic Noises
Poisson noise
- Dominant source of noise in Photograph
- 평균이 0 이지만 signal -dependent 라서 제거하기 어려움
- L2 loss를 사용해서 noise 크기를 λ를 [0, 50] 범위 내에서 변동시킴
- clean targets: 30.59 ± 0.02 dB noisy targets : 30.57 ± 0.02 dB -> 유사한 convergence speed
Multipliicative Bernoulli noise (aka. binomial noise)
- random mask m 을 생성해서 , valid pixel 에 대해서는 1 , zeroed/missing pixel 에 대해서는 0 을 할당함
- missing pixel 에서 gradient를 역전파(backpropagating) 하지 않지 위해 loss에서 제외함


- (a) 가우시안 (σ = 25): 가우시안 노이즈를 적용한 이미지에 대한 복원 결과를 보여줍니다. 비교 방법으로 BM3D가 사용되었습니다.
- (b) 포아송 (λ = 30): 포아송 노이즈를 적용한 이미지에 대한 복원 결과를 보여줍니다. 비교 방법으로는 Anscombe 변환을 사용한 후 BM3D로 디노이징을 수행합니다.
- (c) 베르누이 (p = 0.5): 베르누이 노이즈를 적용한 이미지에 대한 복원 결과를 보여줍니다. 비교 방법으로는 Deep Image Prior가 사용되었습니다
각각의 사례에서 'Ground truth'는 원본 이미지를, 'Input'은 노이즈가 추가된 입력 이미지를, 'Our'은 노이즈에서 복원된 이미지를, 'Comparison'은 다른 비교 방법으로 복원된 이미지. 이 결과들은 노이즈가 있는 타겟을 사용한 복원이 깨끗한 타겟을 사용한 복원과 거의 동일하다는 연구의 결론을 뒷받침
Text removal ( 텍스트 제거 ) : loss 는 무작위 위치에 겹쳐진 무작위 문자열로 구성되며, 폰트 크기 색상도 무작위, 폰트와 문자열의 방향은 고정
훈련 및 테스트 쌍에 손상된 픽셀의 확률 p는 대략 [0, 0.5] 범위이며, 테스팅 중에는 p ≈ 0.25
이 테스트에서 평균 (L2 loss) 사용하지 않음. : overlaid text has colors unrelated to actual image-> 결과 이미지가 올바른 답과 평균 텍스트 색상의 선형 조합(회색)으로 잘못 경향됨
** 어느정도의 중첩된 텍스트가 있다면 pixel은 원래 색상을 더 자주 유지하므로 median(중간값) 이 올바른 통계값이됨 -> L1 loss 사용


Random- valued impulse noise : 일부 pixel 을 noise로 대체하고 다른 pixel 의 색상을 유지함
- standard salt and pepper noise( pixel을 검은색, 흰색으로 무작위 대체 ) 대신,
각 픽셀은 [0,1] 범위의 무작위 색상으로 대체되며p 확률로 균등 분포를 따르고 1-p 확률로 원래 색상을 유지함
- 픽셀의 색상 분포는 원래 색상에 대한 디랙 분포(Dirac distribution)와 균등 분포를 합친 것으로, 이 때 p로부터 대체 확률을 상대적으로 받습니다. 이 경우, 평균도 중앙값도 올바른 결과를 제공하지 않음. 원하는 출력은 분포의 최빈값(mode)입니다(Dirac spike).
- 근사적 모드 탐색을 위해 "L0 loss" 함수를 ε에서 γ까지 점진적으로 감소시키며 사용했습니다.
여기서 ε는 10^-8, γ는 2에서 0까지 선형적으로 감소합니다.

우리는 노이즈가 있는 입력과 노이즈가 있는 타겟을 사용하여 네트워크를 다시 훈련시키는데, 여기서 각 쌍의 손상된 픽셀의 확률 p는 [0, 0.95] 범위에서 무작위로 결정됩니다. 아래 그림은 픽셀의 70%가 무작위화됐을 때의 추론 결과

L2 loss로 훈련하는 것은 결과를 회색으로 강하게 편향시키는데, 이는 결과가 올바른 답과 무작위 충동 손상의 평균인 균등 무작위 손상으로 향하는 선형 조합으로 경향되기 때문입니다. 이론이 예측하듯이, L1 loss은 무작위화된 픽셀이 50% 미만일 경우 좋은 결과를 줍니다. 그러나 그 기준을 넘으면, 어두운 및 밝은 영역이 회색을 향해 빠르게 편향됩니다(. 반면, L0 loss는 심각한 손상(예: 90% 픽셀)에서도 거의 편향을 보이지 않습니다. 왜냐하면 가능한 모든 픽셀 값 중에서 올바른 답(예: 10%)이 여전히 가장 흔하기 때문입니다.
3.3 Monte Carlo Rendering
Monte Carlo path tracing; 물리적으로 정확한 가상 환경의 렌더링 생성하는 과정
- 광원과 가상 센서를 연결하는 무작위 light paths 를 통해 장면의 방사선을 통합
- pixel 강도가 무작위 경로 샘플링 과정의 기대값이 되도록 설계
- 노이즈 분포는 장면에 따라 달라지고 예측하기 어려운 형태로 존재해 gaussian 노이즈 제거보다 훨씬 어려움
- 데이터 생성동안 텍스처 색상과 법선 벡터등의 보조 정보를 활용해 노이즈 감소 가능
High dynamic range (HDR); 밝기값이 서로 수 십 배 차이 날 수 있어 표준화된 범위로 압축해야함
-특정 톤 매핑 연산자를 사용함 . Reinhard's global operator 사용 ( v라는 스칼라 밝기 값을 범위 0-1 사이로 매핑)

몬테카를로 렌더링 방법을 사용해 생성된 이미지는 높은 동적 범위를 가진 픽셀 밝기 값을 포함하며, 이는 표준 디스플레이 장치에서 보여주기 위해 고정 범위로 압축해야 하는 어려움이 있습니다. 연구팀은 라인하르트의 글로벌 톤 매핑 연산자를 변형하여 사용했고, 이는 모든 비음수 밝기 값을 [0,1] 범위로 매핑합니다. 그러나 무한한 범위의 밝기 값을 가지는 HDR 이미지와 이를 처리할 때 비선형 톤 매핑 연산자 사용은 예측 문제를 발생시킬 수 있습니다.
표준 평균 제곱 오차(MSE) 손실 함수는 이미지의 이상치나 꼬리 부분의 영향을 지나치게 받게 될 수 있으며, 결과적으로 노이즈 제거기를 훈련시킬 때 수렴하지 않는 문제가 발생할 수 있습니다. 이에 대한 해결책으로 톤 매핑된 입력을 사용하고 네트워크 출력이 한계에서 정확한 값에 근접하도록 하는 것이 제안되었습니다. 이 방식은 네트워크가 비톤 매핑된 밝기 값을 출력하도록 하면서도 기대값의 정확성을 유지할 수 있게 해줍니다.
이 부분은 몬테카를로 렌더링된 이미지에서 발생하는 노이즈를 효과적으로 제거하기 위한 방법론과 관련된 문제점 및 해결책에 초점을 맞추고 있습니다.
Denoising Monte Carlo rendered images

몬테카를로 렌더링 방식을 이용해 높은 샘플 비율로 렌더링한 이미지와 낮은 샘플 비율로 렌더링하여 생성된 노이즈가 많은 이미지를 대상으로 디노이징 작업을 수행합니다. 연구팀은 860개의 건축 관련 이미지로 이루어진 훈련 세트와 34개의 다른 장면으로 구성된 검증 세트를 사용했습니다. 각 이미지는 높은 샘플 비율(131k spp)로 깨끗한 버전과 낮은 샘플 비율(64 spp)로 노이즈가 있는 두 가지 버전으로 렌더링되었습니다. 디노이징 네트워크는 깨끗한 타겟 이미지로 훈련되었고, 그 결과로 검증 세트에서 높은 PSNR 값을 달성했습니다. 노이즈가 있는 타겟으로도 유사한 훈련을 진행했으며, 이 경우에는 깨끗한 타겟으로 훈련한 경우보다 약간 낮은 PSNR을 기록했지만, 노이즈 타겟을 사용하는 것이 깨끗한 이미지를 생성하는 것보다 훨씬 빠르고 경제적이기 때문에, 이 방법이 상당한 이점을 가짐을 보여주었습니다.
Online training
온라인 트레이닝 방법은 몬테카를로 렌더링된 이미지의 디노이징을 위해 특정 3D 장면(예: 게임 레벨이나 영화 촬영)에 특화된 디노이징 모델을 실시간으로 훈련시키는 과정을 의미합니다. 이 접근법은 특정 장면에 대한 특화된 모델 훈련을 가능하게 하며, 사용자가 장면을 탐색하면서 모델이 배워나가도록 합니다.
실험은 특정 장면을 통과하는 동안 1000개의 프레임으로 디노이저를 스크래치부터 훈련시키는 과정으로 구성되었습니다. NVIDIA Titan V GPU를 사용하여 한 프레임을 훈련하는 데 약 190ms가 소요되었고, 훈련 데이터는 픽셀당 8샘플로 렌더링된 노이즈가 있는 이미지들로 구성되었습니다.
이 방식에서 노이즈가 있는 타겟으로 훈련된 네트워크는 깨끗한 타겟으로 훈련된 네트워크와 유사한 학습 효과를 보였습니다. 하지만, 노이즈가 있는 타겟은 깨끗한 이미지를 생성하는 데 필요한 시간보다 훨씬 짧은 시간(190ms 대 7분)에 렌더링됩니다. 이 결과는 온라인 트레이닝에서 노이즈가 있는 타겟을 사용하는 것이 시간 효율성과 모델 품질 사이에서 좋은 트레이드오프를 제공한다는 것을 보여줍니다.

3.4 Magnetic Resonance Imaging (MRI)
MRI는 생물학적 조직의 입체적 이미지를 생성하기 위해 신호의 Fourier transform (= "k-space")을 샘플링합니다. 현대 MRI 기술은 압축 감지(compressed sensing, CS)에 크게 의존하여 Nyquist-Shannon 한계를 우회합니다. 즉, k-공간을 undersampling하고 적절한 변환 도메인에서 이미지의 희소성을 활용하여 에일리어싱을 제거하는 비선형 재구성을 수행합니다.
3 k-공간 샘플링을 임의 프로세스로 바꾸어 MRI 이미지 복원에 접근하는 방법을 다룹니다. k-공간에서 빈도수가 낮은 부분은 베르누이 과정을 통해 선택되며, 선택되지 않은 빈도는 0으로 설정됩니다. 이러한 '러시안 룰렛' 프로세스를 통해 얻은 결과는 정확한 스펙트럼을 예상할 수 있으며, 이를 통해 전체적인 k-공간 샘플링 비율을 조절할 수 있습니다. 그런 다음 합성된 푸리에 변환을 통해 이미지 도메인으로 다시 변환합니다.
뉴럴 네트워크를 훈련시키기 위해, 두 개의 독립적인 샘플링된 이미지 \( \hat{x} \)와 \( \hat{y} \)를 사용하여 회귀 문제를 설정합니다. 푸리에 변환의 선형성을 이용하며, L2 손실 함수를 사용합니다. 또한, 입력 이미지에 존재하는 빈도수를 정확하게 유지하면서 결과를 푸리에 변환하고, 입력에서 가져온 빈도수로 대체한 후 원래 이미지 도메인으로 되돌리는 과정을 통해 결과를 더 개선합니다. 이 과정은 end-to-end로 훈련됩니다.
실험은 IXI 뇌 스캔 MRI 데이터셋의 2D 슬라이스에서 수행되었습니다. 데이터셋에서 이미지를 재구성한 후, 실제 MRI 샘플의 특성을 모방하여 무작위 샘플을 추출했습니다. 훈련 세트는 50명의 대상에서 추출한 5000개의 256x256 해상도 이미지를 포함하고, 검증 세트는 10명의 대상에서 무작위로 선택한 1000개의 이미지를 포함합니다.
복원의 예로, 10%의 스펙트럼 샘플만 유지된 입력 이미지와, 노이즈가 있는 타겟 이미지로 훈련된 네트워크에 의한 복원된 이미지, 그리고 깨끗한 타겟 이미지로 훈련된 네트워크에 의한 복원된 이미지를 보여줍니다. 노이즈가 있는 타겟 이미지로 훈련된 네트워크는 검증 데이터에서 평균 31.74 dB의 PSNR을 달성했으며, 깨끗한 타겟 이미지로 훈련된 네트워크는 31.77 dB의 PSNR을 달성했습니다. 훈련은 NVIDIA Tesla P100 GPU에서 300 에폭 동안 13시간이 걸렸습니다. 결과적으로, 노이즈가 있는 타겟 이미지로 훈련하는 방법은 비용 효율적이며, 최근의 다른 연구 결과와 비교해도 경쟁력 있는 성능을 보여줍니다.

이 그림은 자기 공명 영상(MRI) 재구성의 예시를 보여줍니다:
- **(a) Input**: 이것은 스펙트럼 샘플의 단지 10%만 유지된 입력 이미지로, 1/p로 스케일되었습니다. PSNR은 18.93 dB입니다.
- **(b) Noisy trg. (노이즈 타겟)**: 입력 이미지와 유사한 노이즈 타겟 이미지로 훈련된 네트워크에 의해 재구성된 이미지입니다. PSNR은 29.77 dB입니다.
- **(c) Clean trg. (깨끗한 타겟)**: 참조 이미지와 유사한 깨끗한 타겟 이미지로 훈련된 네트워크에 의해 재구성된 이미지입니다. PSNR은 29.81 dB입니다.
- **(d) Reference (참조)**: 원본, 손상되지 않은 이미지입니다.
그림 아래쪽에 있는 이미지는 각각의 경우에 대한 스펙트럼을 보여줍니다. PSNR 값은 여기에 표시된 이미지를 기준으로 하며, 전체 검증 세트에 대한 평균 값은 본문에서 설명합니다.
이 그림은 MRI 데이터에서 부족한 스펙트럼 정보를 가진 이미지를 복원하는 과정을 나타냅니다. 노이즈가 있는 타겟과 깨끗한 타겟 모두를 사용하여 훈련된 네트워크의 재구성 능력을 비교하고, 결과적으로 양쪽 모두 유사한 재구성 품질을 보임을 보여줍니다.
4. Discussion
깨끗한 데이터 없이도 깊은 신경망을 통한 신호 복원이 가능함을 강조하고 있습니다. 특히 BM3D와 같은 기존 알고리즘뿐만 아니라 최신의 AmbientGAN 방법론을 비교하며, 두 방식 모두가 손상된 데이터로부터 유용한 정보를 추출할 수 있는 가능성을 보여주고 있음을 논하고 있습니다. 이는 신호 처리와 이미지 복원 분야에서 깨끗한 데이터 수집의 부담을 줄이고 효율성을 높일 수 있는 새로운 기술 발전을 시사합니다.